در گردش کارها ممکن است در وضعیتهای خاصی نیاز به فراخوانی اطلاعات از پایگاه داده های دیگر (خارج از پایگاه مدیریت فرایندها) داشته باشیم. برای این کار، سه راه حل وجود دارد:
- استفاده از API: در صورتی که برای خواندن اطلاعات از پایگاه داده مورد نظر، API پیاده سازی شده باشد بهترین راه حل استفاده از این روش است. برای مثال در حال حاضر برای خواندن اطلاعات از سیستم یکپارچه مالی نوسا، این API وجود دارد.
- استفاده از کلاس WorkADOSelect: در صورت نبودن API راه حل جایگزین، فراخوانی اطلاعات مورد نظر توسط Query و به شکل مستقیم از پایگاه داده هاست. این روش علاوه بر پیچیدگیها و دشواریهای مرتبط با برنامه نویسی، چالشهای همگام سازی توابع فراخوانی با تغییرات پایگاه داده ها و نیز مدیریت دسترسی و امنیت داده ها را به همراه دارد.
- فراخوانی اطلاعات از یک فایل متنی ساختاریافته: در موارد متعددی می توانیم از روش فراخوانی از یک فایل متنی استفاده کنیم که اهم این موارد به شرح زیر است:
- پایگاه داده مبدا یا وجود ندارد (مثلا اطلاعات به شکل دستی در Excel ذخیره می شود)
- به دلایل امنیت داده ها نمی خواهیم دسترسی با WorkADOSelect را به کاربر بدهیم.
- به دلیل پیچیدگی پایگاه مقصد، امکان پیاده سازی الگوی جستجو و فیلترینگ در پایگاه مقصد بسیار دشوار و هزینه بر است.
- منطق تعیین رکوردها مشخص نیست. یعنی این که ممکن است پایگاه داده وجود داشته باشد، حتی API هم تعریف شده باشد اما معیار انتخاب رکوردها کاملا فرموله و معین نبوده و براساس معیارهای شخصی، لحظه ای و سیال باشد. برای مثال فرض کنید می خواهیم مشتریان بزرگ را انتخاب کنیم. در این مورد معیار خیلی مشخصی برای درجه و میزان بزرگی مشتری وجود ندارد و معمولا با نگاه به فهرست مشتریان و به شکل لحظه ای و غیرقطعی انجام می شود.
مفهوم متن ساختاریافته
متن ساختاریافته به متنی گفته می شود که در آن، اطلاعات در قالب سطرها و ستونها و با جداکننده های معین ذخیره شده است. در این متنها هر سطر، یک رکورد اطلاعاتی است و هر ستون، یک فیلد اطلاعاتی می باشد. برای مثال به متن زیر توجه کنید:
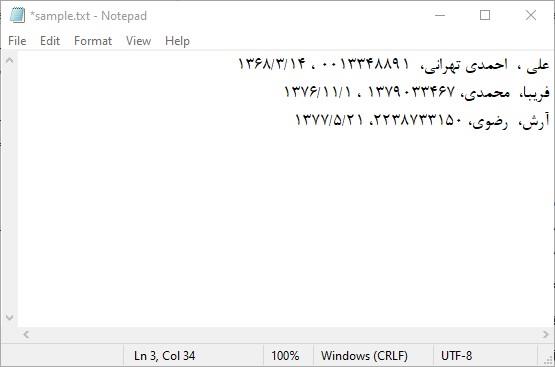
ملاحظه می کنید که در این متن، هر سطر، مربوط به یک شخص است و در هر سطر چهار ستون وجود دارد که به ترتیب نام، نام خانوادگی، کد ملی و تاریخ تولد می باشد. در این مثال، جداکننده ستونها، کاما (،) و جداکننده سطرها، کاراکتر CR+LF (انتقال به ابتدای سطر بعد) می باشد.
نکته : از آنجایی که ممکن است کاراکتر کاما در اطلاعات موجود باشد، این کاراکتر برای جداکننده مناسب نیست و به همین دلیل، معمولا کاراکترهای دیگری مانند Tab، نقطه کاما ( ; ) ، ESC، فاصله (space) ، خط عمودی (|) و ...برای جداکننده استفاده می شود.
فرمت CSV استاندارد پرکاربرد متن ساختاریافته
یکی از فرمتهایی که بطور معمول برای تولید متنهای ساختاریافته استفاده می شود فرمت CSV (Comma Separated) UTF-8 است. در حال حاضر، برنامه صفحه گسترده Excel که بسیار رایج و پراستفاده است امکان خروجی به فرم CSV را دارد. به همین دلیل در ادامه نحوه تهیه خروجی CSV را در Excel توضیح می دهیم.
نحوه تهیه خروجی فرمت CSV در Excel
برای نمونه، فرض کنید مثال بالا را در Excel ذخیره کرده ایم:
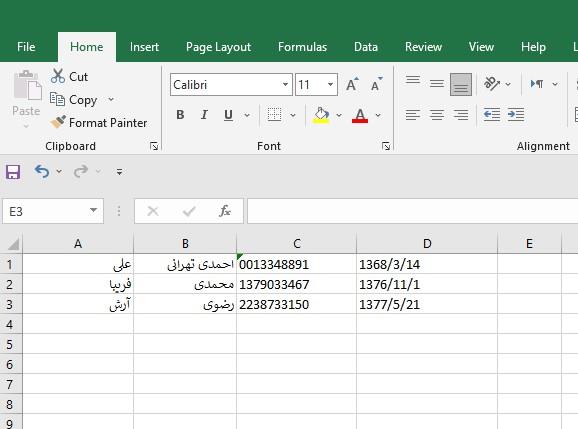
حال برای خروجی CSV باید ابتدا منوی File را باز کنید تا محاوره به شکل زیر روی صفحه باز شود:
در این محاوره روی گزینه Save As کلیک کنید تا محاوره ذخیره فایل به شکل زیر باز شود:
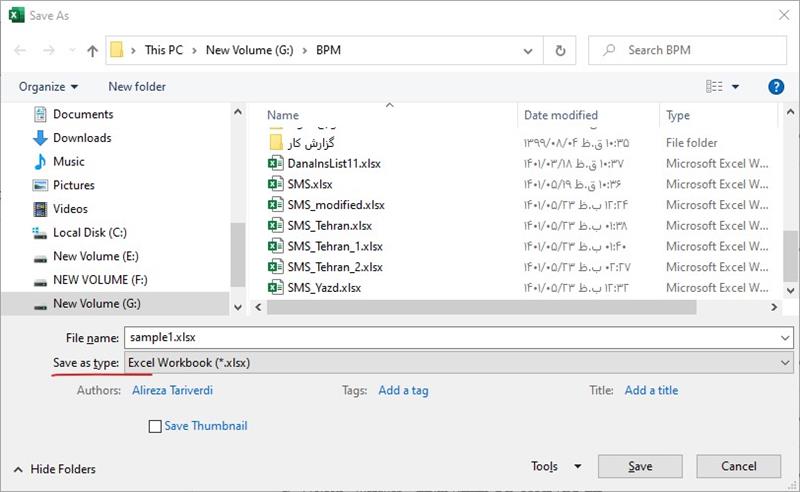
در این محاوره نام و مسیر فایل را تعیین کنید و در انتها فهرست فرمتهای خروجی (Save as type) را به شکل زیر باز کنید:
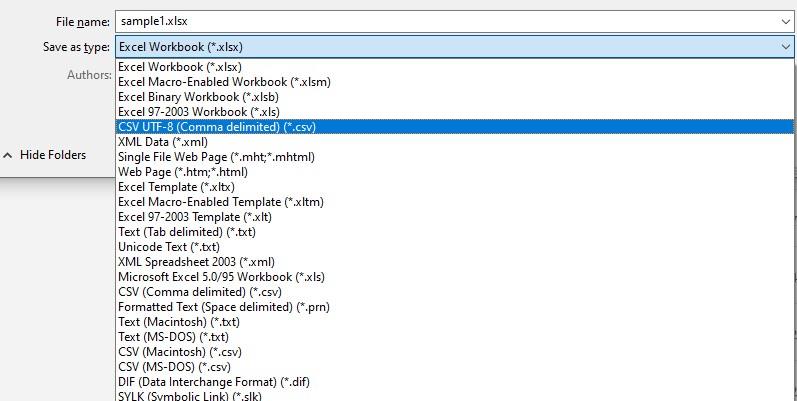
همانطور که مشاهده می کنید در این لیست باید گزینه CSV UTF-8 (Comma Delimited) (*.csv) را انتخاب کنید و در انتها تکمه Save را کلیک کنید. به این ترتیب فایل متنی به فرمت CSV ذخیره می شود. حال می توانیم این فایل را در یک ویرایشگر متنی مثلا notepad++ باز کنیم که به شکل زیر خواهد بود:
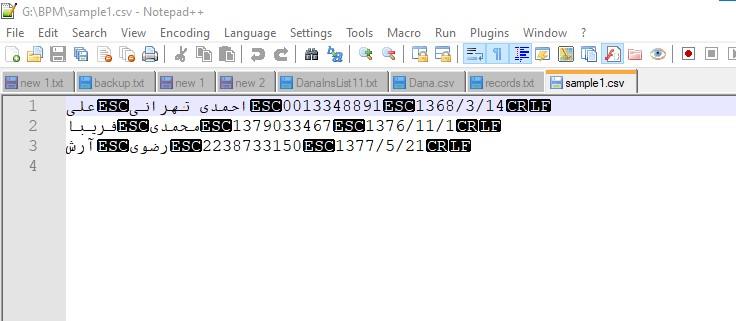
همانطور که می بینید در اینجا، برای جداکننده سطرها از CRLF (انتقال به ابتدای سطر بعد) و برای جداکننده ستونها، بجای کاما از کاراکتر ESC استفاده شده است.
فراخوانی فایل متنی در یک آرایه
برای فراخوانی اطلاعات یک فایل متنی در برنامه فرایند، ابتدا باید این فایل را به کار پیوست کنیم. سپس باید این پیوست را در یک فیلد منبع دیجیتال کار ذخیره کنیم و در مرحله آخر در یک تابع اجرایی، فایل متنی را سطر به سطر بخوانیم و ستونها را به ترتیب در فیلدهای یک آرایه ذخیره کنیم. در ادامه، جزئیات این مراحل شرح داده شده است:
پیوست فایل متنی به کار
اولین گام این است که همانند شکل زیر، فایل متنی شامل اطلاعات ساختاریافته را به کار ضمیمه یا پیوست کنید:
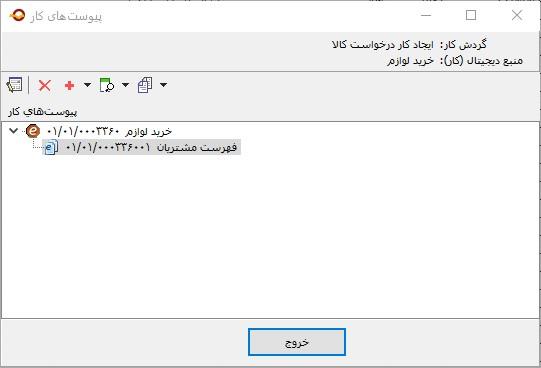
در این مثال، یک فایل متنی با شرح فهرست مشتریان به کار خرید لوازم پیوست شده است.
انتخاب پیوست در یک فیلد منبع دیجیتال کار
از آنجایی که هر کار می تواند به تعداد نامحدودی پیوست داشته باشد، لذا لازم است همانند شکل زیر، از میان پیوستهای موجود، پیوست مورد نظر خود برای فراخوانی اطلاعات را به نوعی مشخص کنیم. به این منظور، بهترین راه حل این است که یک فیلد منبع دیجیتال کار داشته باشیم و پیوست مورد نظر خود را در این فیلد تعیین و ذخیره کنیم.
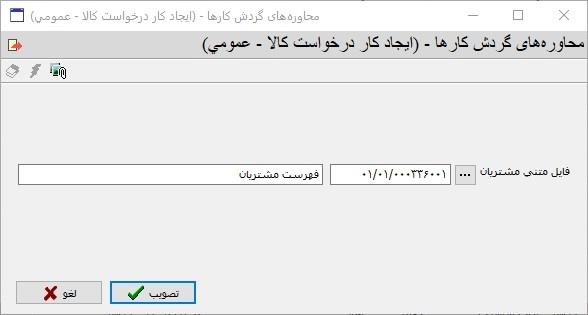
ملاحظه می کنید که پیوست فهرست مشتریان، در این فیلد انتخاب و ذخیره شده است و لذا از این پس از طریق محتوای این فیلد (کلید منبع دیجیتال پیوست)، می توانیم به فایل متنی مشتریان دسترسی داشته باشیم.
فراخوانی فایل متنی در یک تابع اجرایی
در اینجا با ارائه یک فایل اجرایی نمونه که مربوط به فراخوانی فایل متنی مثال بالاست، با جزئیات برنامه نویسی برای فراخوانی اطلاعات فایل متنی آشنا می شویم.

برای آشنایی بیشتر با جزئیات این تابع، در ادامه، سطر به سطر این تابع بررسی می شود:
- const dKey=WorkState2.custTextFile
در این مرحله، محتوای فیلد منبع دیجیتال حاوی پیوست در یک ثابت بنام dKey قرار می گیرد.
- var txt=WorkState2.GetChildDOText(dKey)
در این مرحله، از طریق متد GetChildDOText محتوای متنی فایل پیوست خوانده می شود و در یک متغیر بنام txt قرار می گیرد. از این پس این رشته حرفی مبنای استخراج اطلاعات قرار می گیرد.
- Const myArray=txt.split(“\r" )
همانطور که قبلا گفته شد، جداکننده سطرها CRLF است که می توانیم کاراکتر CR (Carriage Return) را مبنای تفکیک سطرها قرار دهیم. لذا در این مرحله با استفاده از متد split و براساس CR سطرها را از هم تفکیک می کنیم و در یک آرایه بنام myArray ذخیره می کنیم. نکته ای که باید توجه کنید این است که عبارت “\r” در جاوااسکریپت به معنی CR است.
تا اینجا سطرها را از هم تفکیک کرده ایم. گام بعدی این است که در هر سطر، ستونهای اطلاعاتی را از هم تفکیک کنیم.
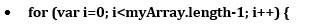
از آنجایی که تعداد سطرها بیش از یک سطر می باشد لذا باید یک حلقه تعریف کنیم و داخل این حلقه به تعداد سطرها، عمل تفکیک را انجام دهیم. در اینجا این حلقه ایجاد می شود.
- var detArray=myArray.split("\x1B" )
همانطور که گفته شد، جداکننده ستونها، کاراکتر ESC است. با توجه به این که این کاراکتر را نمی توانیم به شکل یک رشته حرفی تایپ کنیم لذا باید مقدار هگزادسیمال آن (1B) را به عنوان پارامتر split تعیین کنیم. البته در این مورد قرارداد این است که این مقدار بصورت “\x1B” پاس شود. در این روش عبارت \x نشانگر Hex بودن پارامتر است. به این ترتیب در اینجا هر سطر براساس این جداکننده تفکیک شده و در آرایه ای بنام detArray قرار می گیرد. به عبارت دیگر، هر ستون اطلاعاتی یکی از عناصر آرایه detArray خواهد بود. حال باید این عناصر را در فیلدهای جزئی آرایه مشتریان (customers) مقداردهی کنیم.
if (detArray[0]) { WorkState2.customers.firstName=detArray[0]}
if (detArray[1]) {WorkState2.customers.lastName=detArray[1]{
if (detArray[2]) {WorkState2.customers.melliCode=detArray[2]{
if (detArray[3]) {WorkState2.customers.melliCode=detArray[3]{
همانطور که در فایل متنی مشاهده کردید، آرایه هر سطر (detArray) شامل چهار عنصر است که به ترتیب نام، نام خانوادگی، کد ملی و تاریخ تولد مشتری است لذا در این مرحله، این چهار ستون را که از اندیس صفر تا 3 می باشند، در فیلدهای منتاظر آرایه مشتریان (customers) مقداردهی می کنیم.
نکته: دقت کنید که قبل از هر مقداردهی باید وجود عناصر آرایه detArray را چک کنید در غیر این صورت با پیغام خطا روبرو خواهید شد.
به این ترتیب، آرایه مشتریان به شکل زیر مقداردهی می شود:
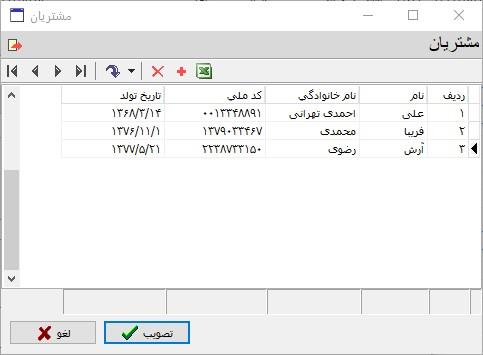
در این مرحله، اطلاعات مشتریان از فایل متنی به آرایه مشتریان منتقل شده است. از این پس می توانید از این آرایه در پردازشهای بعدی گردش کار استفاده کنید.